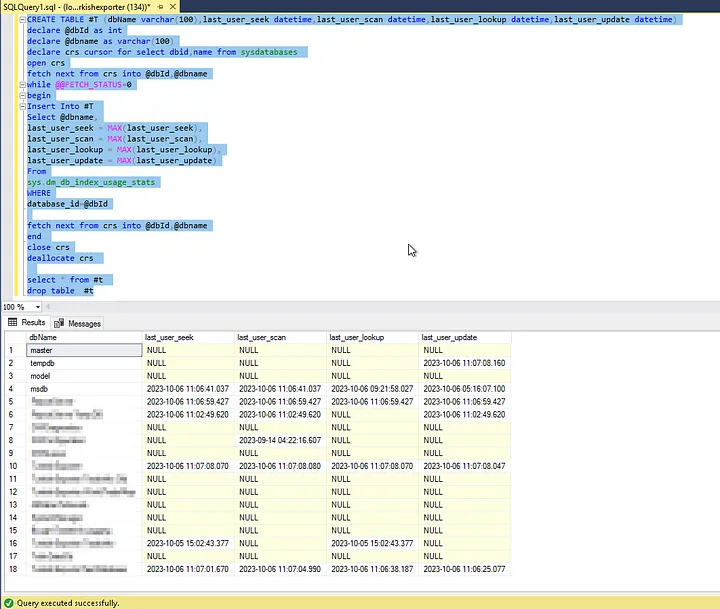
Indexlerin bozulma oranlarını belirlemek ve düzeltmek için SQL sorgusu kullanma konsepti oldukça önemlidir. Bu sorgu, veri tabanlarının performansını artırmak için indexlerin nasıl bakım gerektirdiğini anlamak için kullanışlı bir araçtır. Aşağıda verilen SQL sorgusunu kullanarak index bozulma oranlarını kontrol etme ve gerektiğinde düzeltme sürecini anlatacağım.
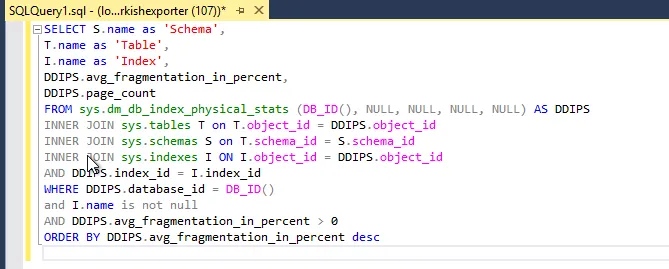
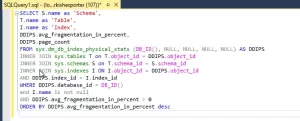
SQL Sorgusu:
SELECT S.name as 'Schema',
T.name as 'Table',
I.name as 'Index',
DDIPS.avg_fragmentation_in_percent,
DDIPS.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) AS DDIPS
INNER JOIN sys.tables T on T.object_id = DDIPS.object_id
INNER JOIN sys.schemas S on T.schema_id = S.schema_id
INNER JOIN sys.indexes I ON I.object_id = DDIPS.object_id
AND DDIPS.index_id = I.index_id
WHERE DDIPS.database_id = DB_ID()
and I.name is not null
AND DDIPS.avg_fragmentation_in_percent > 0
ORDER BY DDIPS.avg_fragmentation_in_percent desc
Bu SQL sorgusu, mevcut veri tabanındaki indexlerin bozulma oranlarını ve sayfa sayısını listeleyecektir. Indexlerin bozulma oranlarının ne kadar olduğunu anlamak önemlidir, çünkü bu, indexlerin nasıl düzeltileceğini belirlememize yardımcı olur.
Ardından, bu sorgunun çıktıları, bir Excel tablosuna kopyalanabilir ve aşağıdaki Excel formülü kullanılarak otomatik olarak index düzeltme sorguları üretilebilir:
=EĞER(D2>10;BİRLEŞTİR("ALTER INDEX ";C2;" ON ";B2;" ";EĞER(D2<30;"REORGANIZE";"REBUILD");" WITH(ONLINE=ON)";"");"")Bu Excel formülü, index bozulma oranına göre ALTER INDEX sorgularını otomatik olarak oluşturur. Index bozulma yüzdesi 10’dan büyükse ve 30’dan küçükse, REORGANIZE işlemi uygulanır; aksi takdirde, REBUILD işlemi uygulanır.
Bu makale konsepti, veri tabanı yöneticilerinin SQL Server veya benzeri veri tabanı sistemlerinde index bakımını otomasyonlaştırarak veri tabanı performansını artırmalarına yardımcı olacaktır. Index bakımının düzenli olarak yapılması, veri tabanı performansını optimize etmek için kritik bir adımdır.
REORGANIZE ve REORGANIZE işlemleri sql de neye göre belirlenir?
SQL Server’da index bakımı için “REORGANIZE” ve “REBUILD” işlemleri, indexlerin bozulma derecesine ve veri tabanının ihtiyaçlarına göre belirlenir. İşte bu kararı etkileyen faktörler:
1.Index Bozulma Oranı (avg_fragmentation_in_percent): Indexlerin bozulma oranı, bir indexin ne kadar fragmente olduğunu gösteren önemli bir ölçüttür. Bozulma oranı, SQL Server tarafından otomatik olarak hesaplanır ve sys.dm_db_index_physical_stats işlevi kullanılarak elde edilebilir. Genellikle, aşağıdaki kurallar kullanılarak belirlenir:
- Bozulma oranı %0–10 arasında ise, index normal kabul edilir.
- Bozulma oranı %10–30 arasında ise, “REORGANIZE” işlemi uygulanabilir.
- Bozulma oranı %30’dan büyükse, “REBUILD” işlemi gerekebilir.
2.Veritabanı Yükü ve Veri tabanı Kullanım Deseni: Veri tabanının yükü ve kullanım deseni de index bakımını etkiler. Eğer bir veri tabanı çok yoğun bir şekilde yazılıyorsa veya çok fazla işlem görüyorsa, bakım işlemlerini yaparken dikkatli olunmalıdır. Bu tür durumlarda “REORGANIZE” işlemi tercih edilebilir, çünkü daha hafif bir işlemdir. “REBUILD” işlemi daha agresif ve kaynak yoğun bir işlem olduğu için dikkatli bir planlama gerektirir.
3.Veritabanı Boyutu ve Kaynaklar: Veri tabanının boyutu ve mevcut kaynaklar da bakım kararlarını etkiler. “REBUILD” işlemi daha fazla kaynak gerektirir, bu nedenle büyük veri tabanlarında bu işlem daha fazla zaman alabilir ve kaynaklarınızı daha fazla etkileyebilir. Küçük veri tabanları için “REBUILD” işlemi daha az sorun yaratabilir.
4.Veritabanının Kritikliği: Veri tabanının kritikliği, bakım işlemleri için ne kadar süre ve kaynak ayrılacağını belirler. Kritik veri tabanlar için bakım işlemleri daha dikkatli bir şekilde planlanmalıdır.
5.İşletim Sistemi ve Donanım: İşletim sistemi ve donanım kaynaklarının veri tabanına tahsis edilme durumu da önemlidir. Daha güçlü bir donanıma sahipseniz, “REBUILD” işlemini daha sık tercih edebilirsiniz.
Bunlar, index bakımı için “REORGANIZE” ve “REBUILD” işlemlerini belirlemede dikkate alınması gereken temel faktörlerdir. Her veri tabanı farklıdır ve özel gereksinimlere sahip olabilir, bu nedenle bakım işlemleri veri tabanınızın ihtiyaçlarına göre uyarlanmalıdır. İdeal olarak, düzenli aralıklarla index bozulma oranları izlenmeli ve veri tabanı yönetimi politikalarınıza uygun olarak bakım işlemleri planlanmalıdır.
Meraklıları için aşağıda bu kodun ayrıntılı açıklamalarını bulabilir;
1.SELECT İfadesi: Bu ifade, sorgunun sonuç kümesinin hangi sütunları içereceğini belirler. Aşağıda kullanılacak sütunların isimleri ve bazılarına verilen takma adlar (alias) bulunmaktadır.
S.name as 'Schema': Şema adını temsil eden sütun, takma adı ‘Schema’ olarak verilmiştir.T.name as 'Table': Tablo adını temsil eden sütun, takma adı ‘Table’ olarak verilmiştir.I.name as 'Index': Index adını temsil eden sütun, takma adı ‘Index’ olarak verilmiştir.DDIPS.avg_fragmentation_in_percent: Ortalama bozulma yüzdesini temsil eden sütun.DDIPS.page_count: Sayfa sayısını temsil eden sütun.
2.FROM İfadesi: Bu ifade, verilerin alınacağı kaynağı belirler. Bu sorguda sys.dm_db_index_physical_stats işlevi kullanılarak veritabanındaki indexlerin fiziksel istatistikleri alınır.
sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) AS DDIPS: Bu işlev, veritabanındaki indexlerin fiziksel istatistiklerini döndürür. DB_ID() ile mevcut veritabanının kimliği alınır. AS DDIPS ise bu sonuç kümesine verilen bir takma adıdır.
3.INNER JOIN İfadeleri: Bu ifadeler, verilerin birleştirilmesi için kullanılır. Sorguda, sys.tables, sys.schemas, ve sys.indexes tabloları ile sys.dm_db_index_physical_stats sonuçları birleştirilir. Bu, ilgili tablo, şema ve index bilgilerinin bir araya getirilmesini sağlar.
4.WHERE İfadesi: Bu ifade, sorgu sonuçlarının filtrelenmesi için kullanılır. Bu sorguda, yalnızca belirli koşulları karşılayan indexler dahil edilir. Örneğin, bozulma oranı 0’dan büyük olan indexler alınır ve null olmayan indexler seçilir.
5.ORDER BY İfadesi: Bu ifade, sonuçların nasıl sıralanacağını belirler. Sorgu sonuçları bozulma yüzdesine göre büyükten küçüğe sıralanır, yani en bozuk indexler önce listelenir.
Herhangi bir sorunuz veya eklemek istediğiniz detaylar varsa bana yazmaktan çekinmeyin.